1. Idée principale
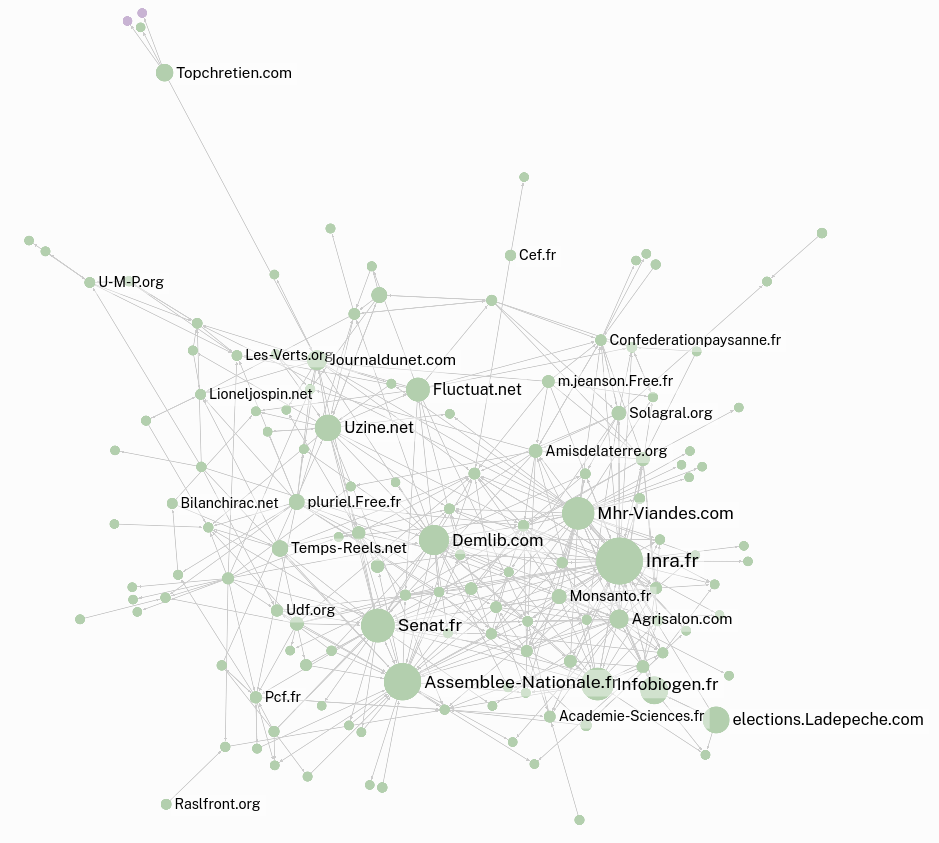
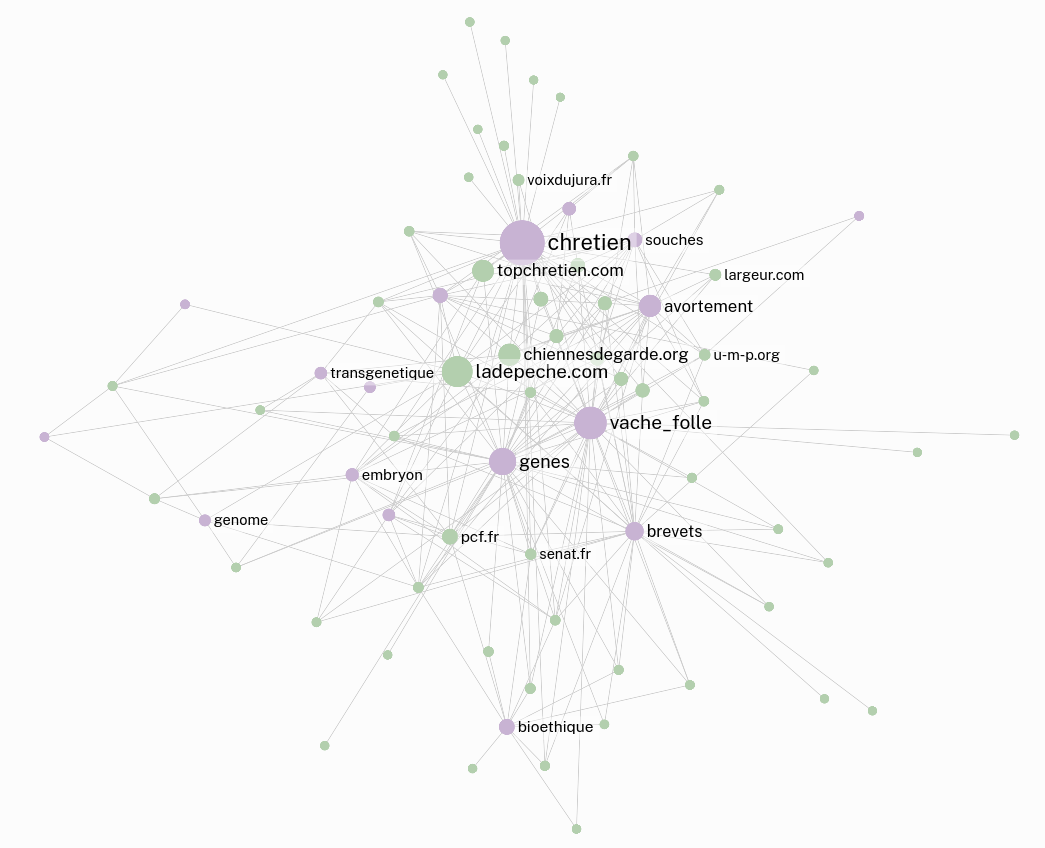
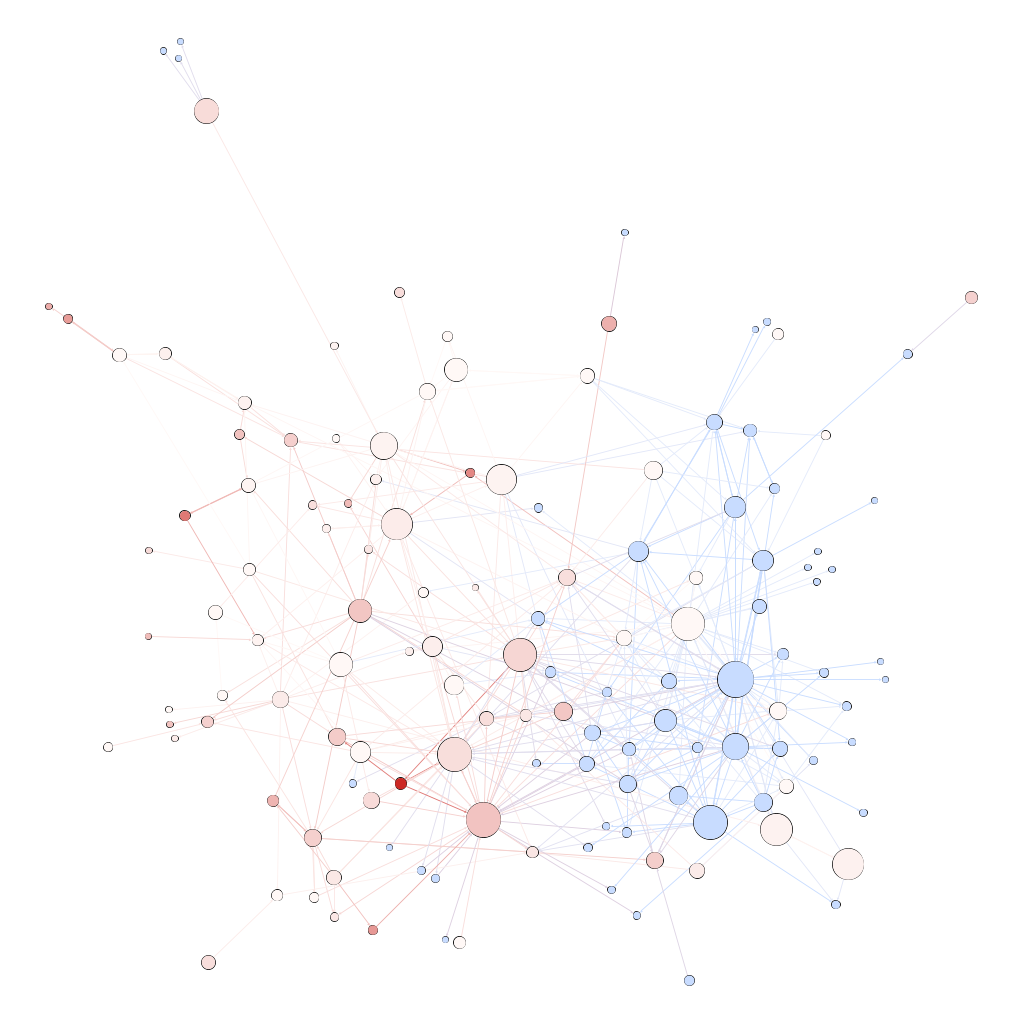
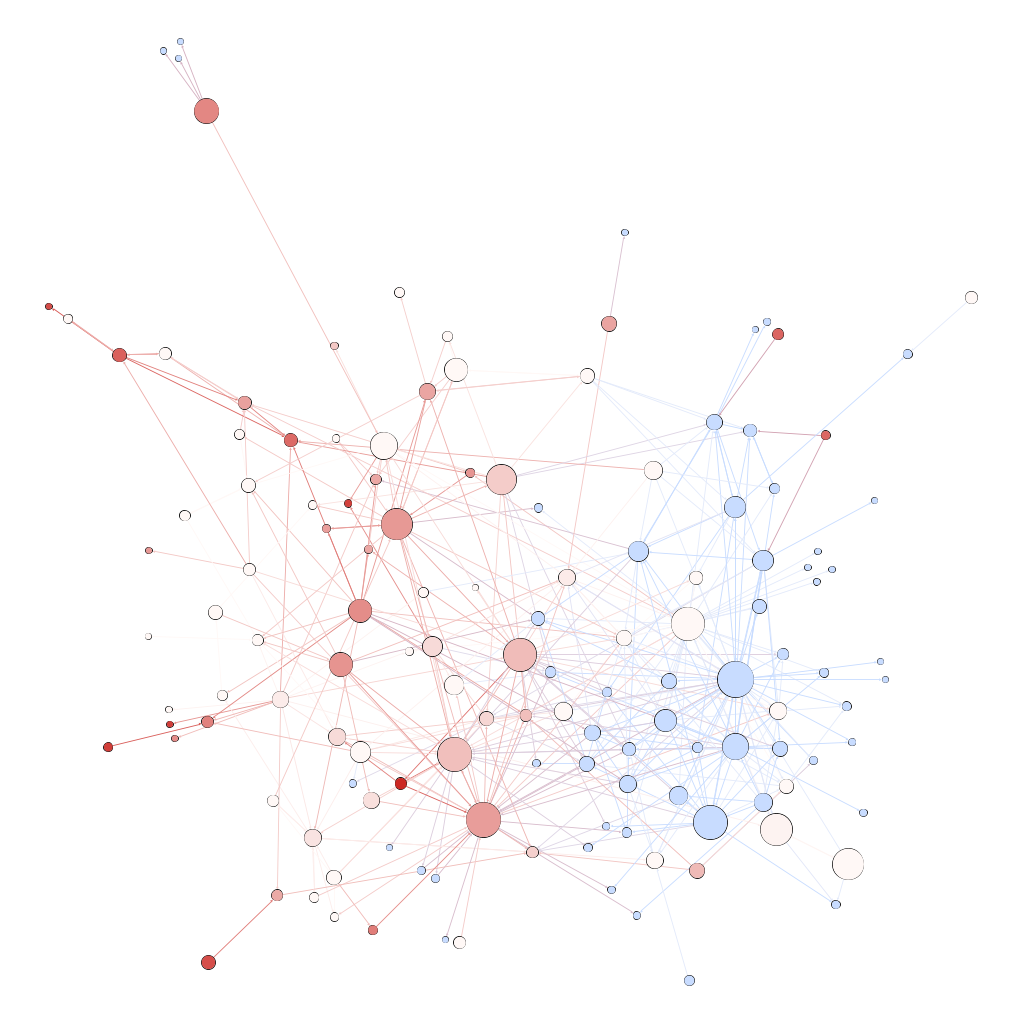
L’objet de cet atelier était de commencer à explorer ce que pouvait représenter l’idée de “génome” dans l’internet politique français au début des années 2000. Les études des représentations politiques du génome sur l’internet français sont difficiles à mener à partir des années 2010. Les auteurs des sites web militants qui écrivaient sur ces sujets les ont peu à peu abandonnés au profit de la création de communautés sur les réseaux sociaux. Le travail de ce groupe s’est donc focalisé sur la constitution d’un corpus autour des représentations politiques du “vivant génomique” à partir des archives du web mises à disposition par la BnF avec pour idée d’observer l’évolution de communautés. C’est pour cette raison que le groupe a travaillé, en majorité, sur l’archive “Elections 2002” collectée via l'application BnF Collecte du web (BCweb) et indexée, en texte intégral, par le logiciel Solr Wayback.
Le sujet de cette expérimentation a la particularité d’être précis et bien défini alliant une sélection pertinente des URLS à inspecter via l’outil Hyphe et un important travail de catégorisation (tagging) des web entités. Il pose aussi les bases d’un potentiel comparatif entre différentes approches, ici la recherche via méthodes statistiques sur corpus indexé en plein texte versus l’exploration qualitative que permet Hyphe.