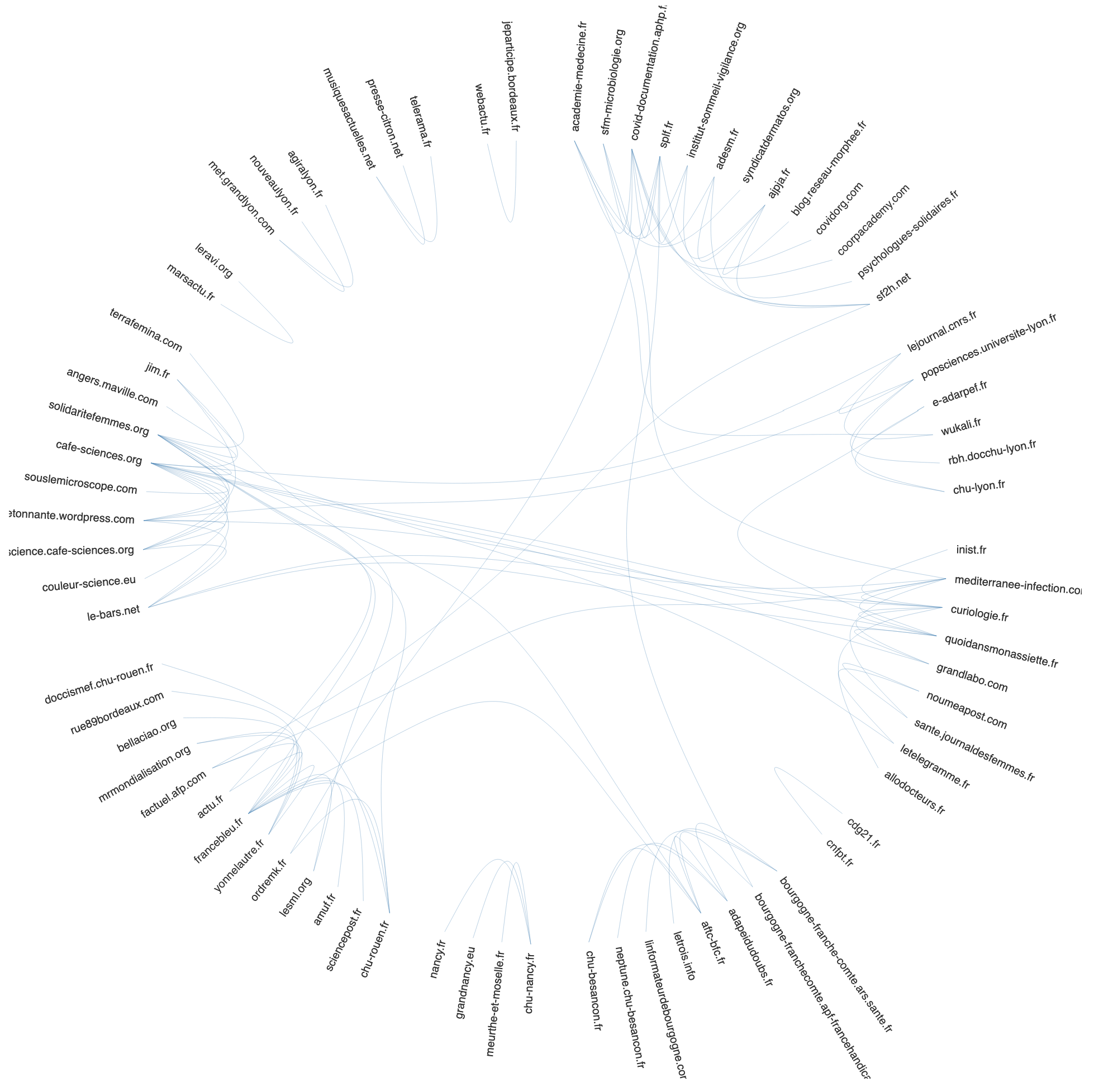
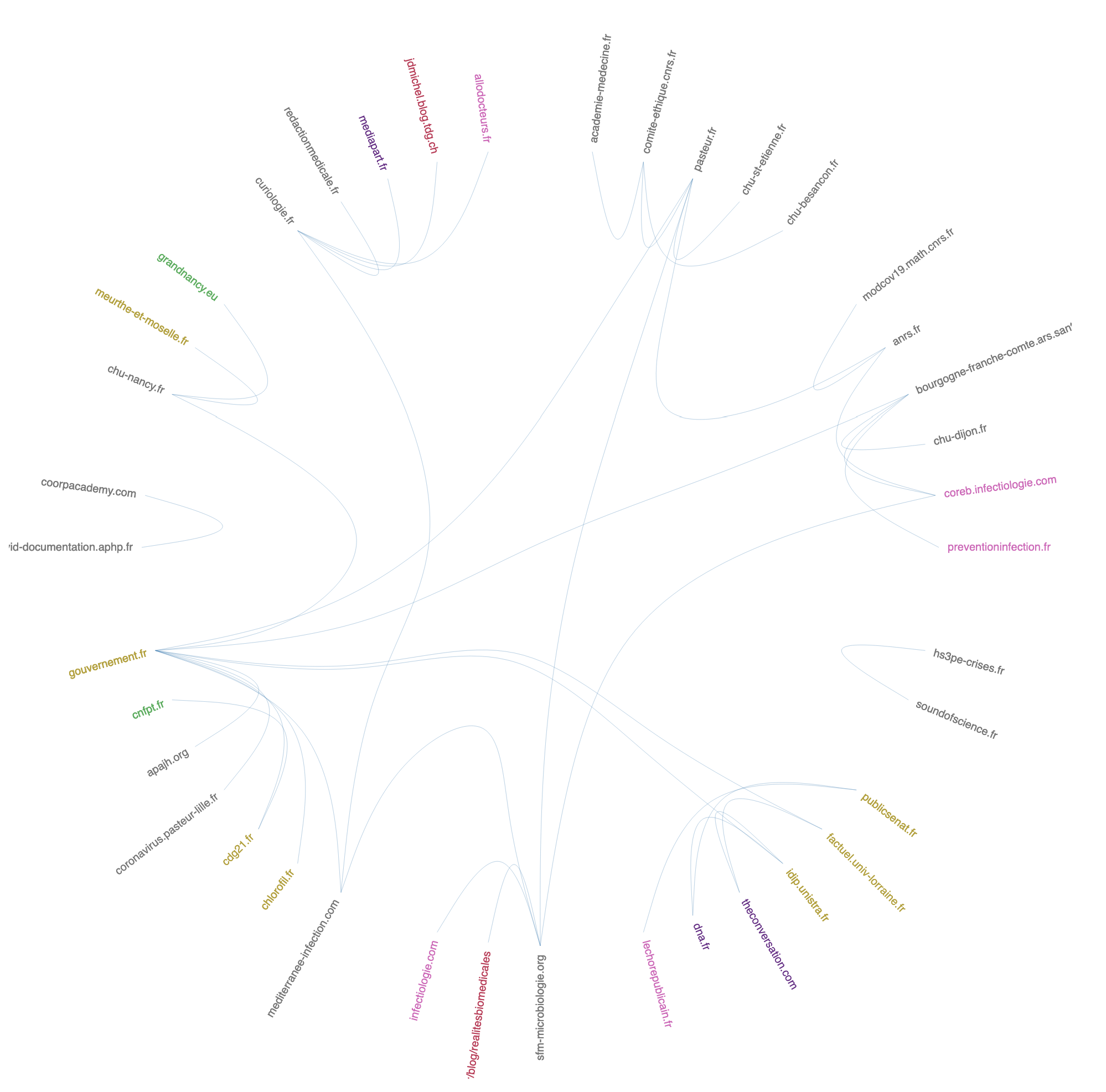
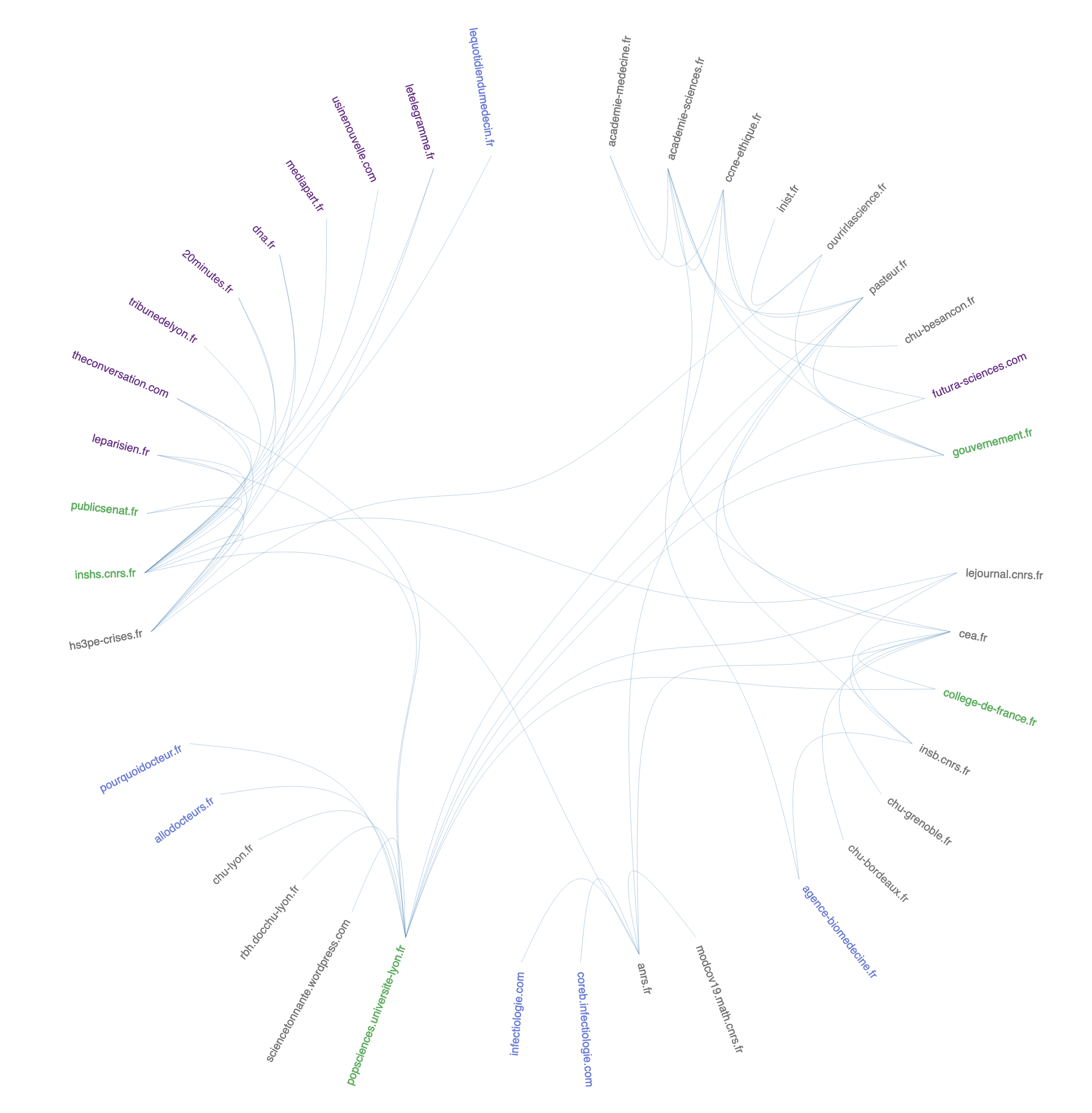
De fait, deux sites occupent une place plus centrale qu’attendue dans la cartographie. Le site de l’IHU Méditerranée infection à la fois en relation avec les sites de vulgarisation scientifique et les sites des grands médias presse et, dans un autre espace de la cartographie, le site Société Française de Microbiologie plus en lien avec les autres institutions de recherche et les CHU. La mise en place de plateforme documentaire et de veille par les acteurs du système de santé explique une autre observation faite, à savoir la présence dans la cartographie de revues scientifiques anglos-saxonnes de référence (The Lancet, National Library of Medicine) qui peut également être rattaché à un mouvement temporaire d’open access.
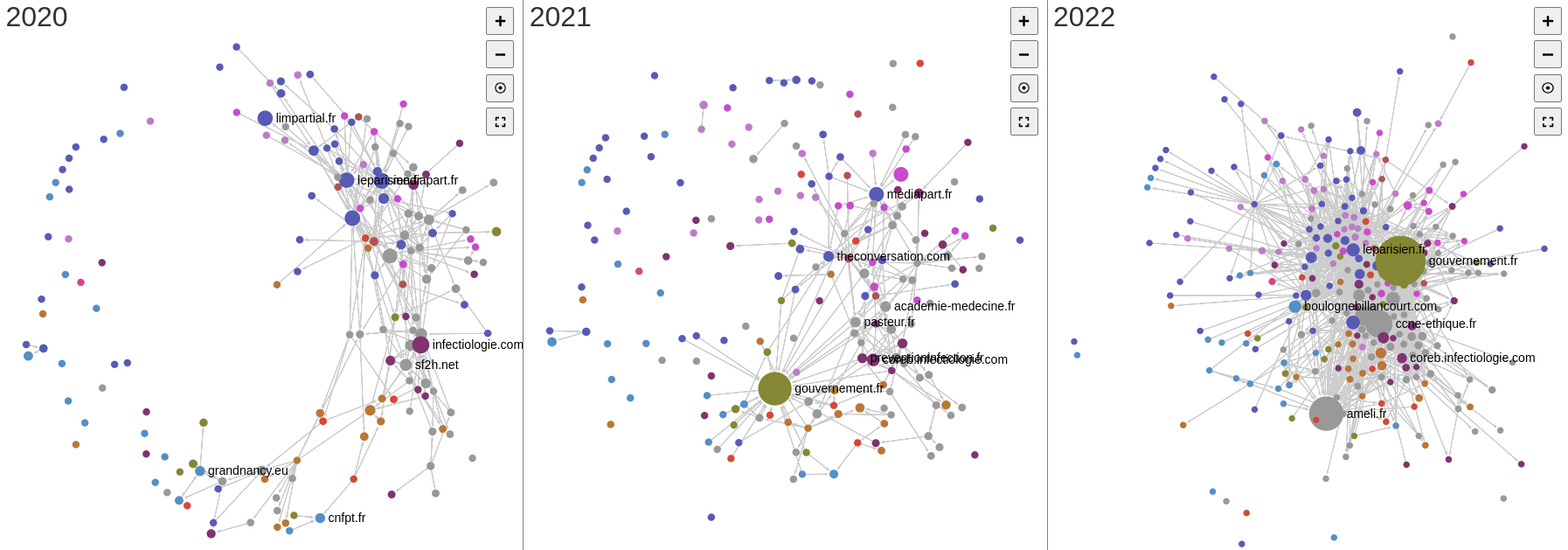
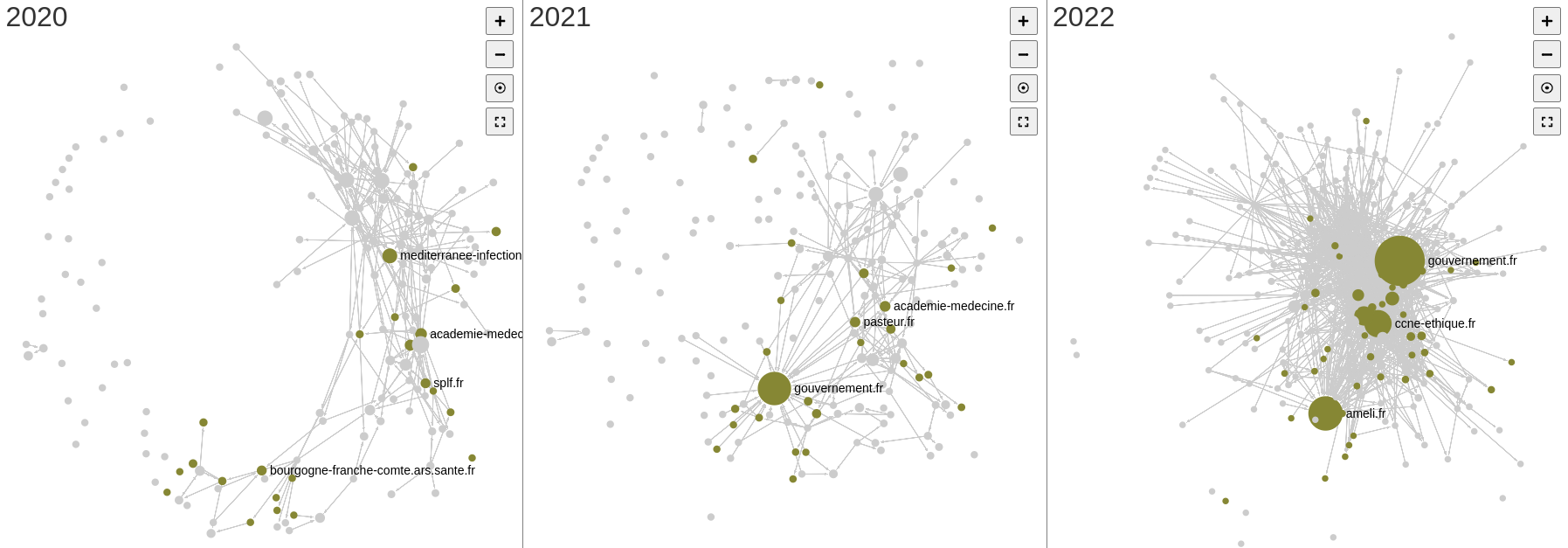
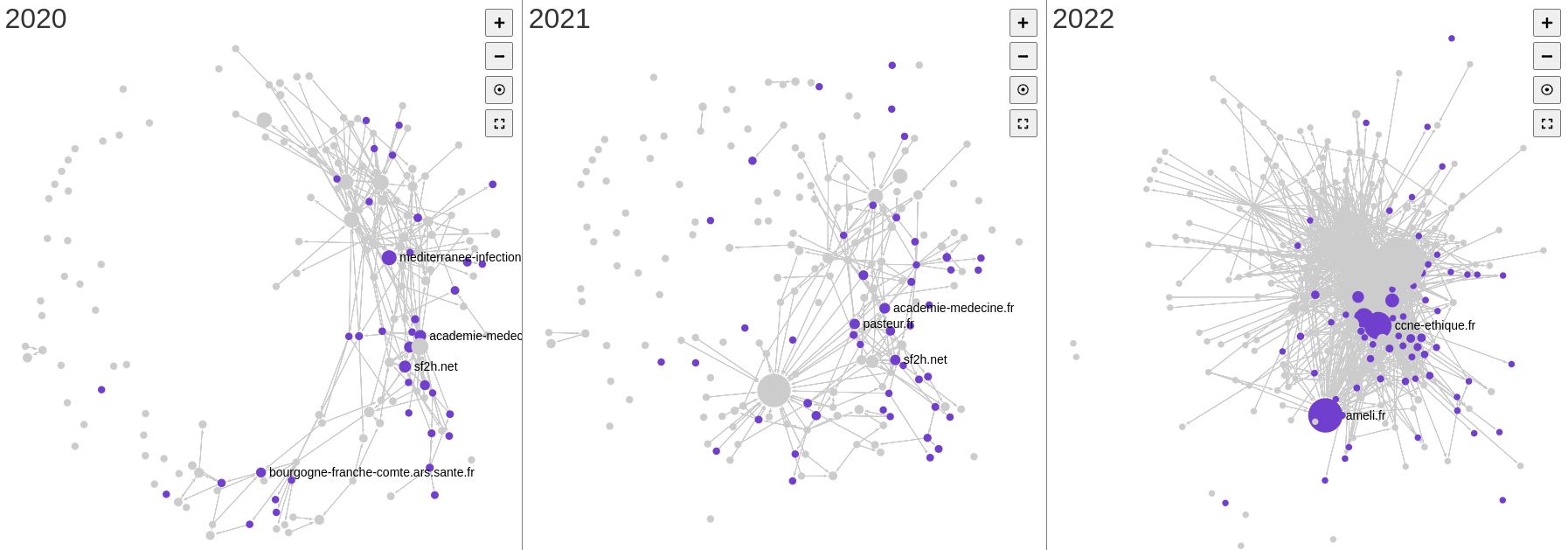
En 2020, “Méditerranée infection” cite les acteurs institutionnels “CNRS” et “defense.gouv.fr”. On observe que les nœuds présents en 2020 et 2022 ne sont pas les mêmes : même si les institutions restent les nœuds centraux, il y a un resserrement sur Sante.fr.
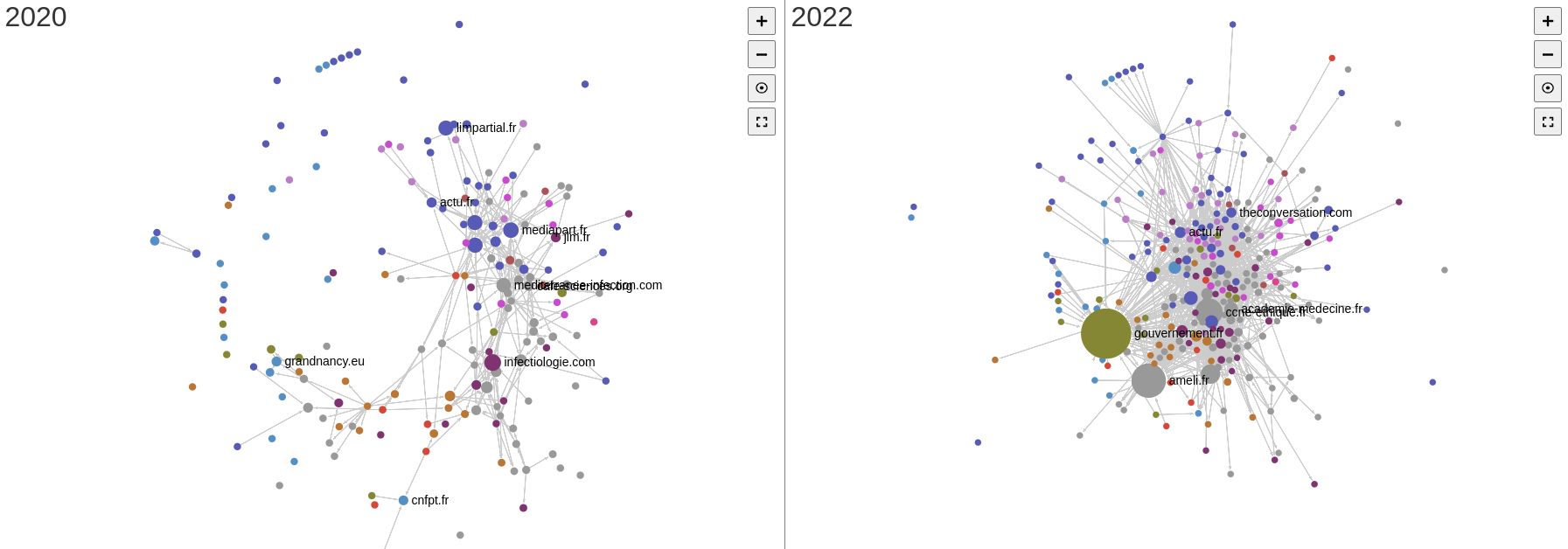
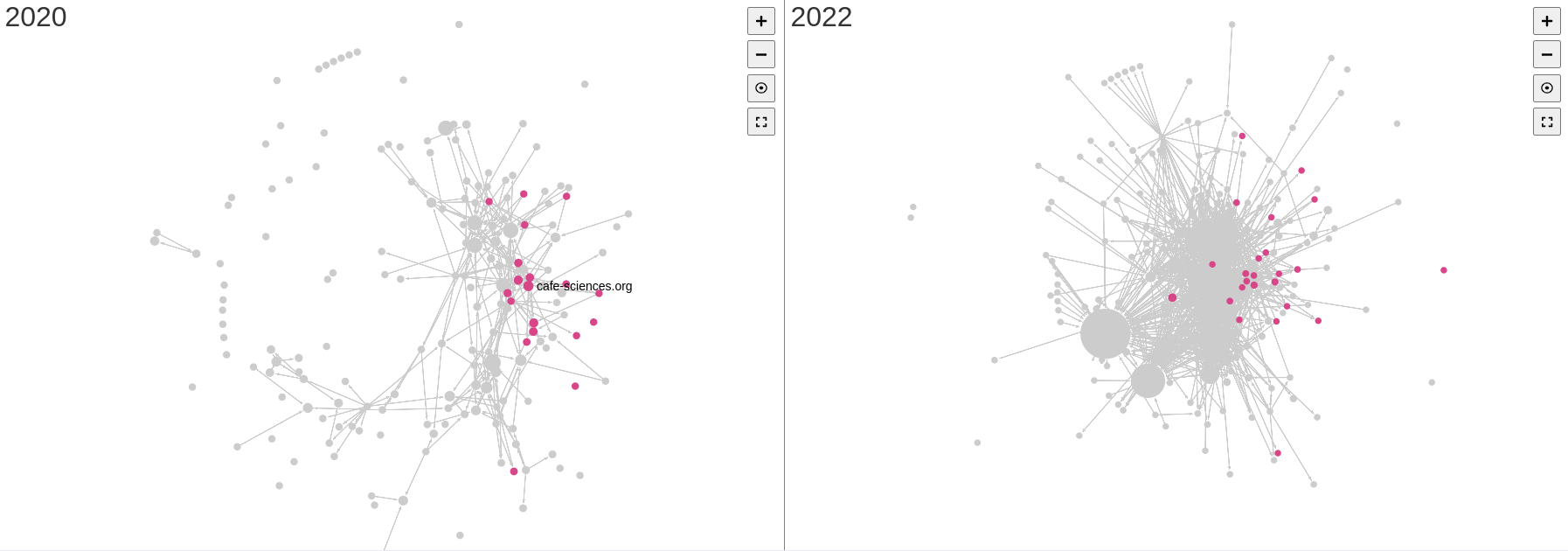
Pour revenir sur l’hypothèse initiale, la comparaison de des deux cartographies tend à démontrer que les institutions restent des nœuds importants en 2022 comme en 2020. Cette comparaison n’est cependant pas aisée. En effet, malgré un périmètre identique puisque les mêmes seeds de départ ont été utilisées pour 2020, 2021 et le web vivant de 2022, les crawls ont des caractéristiques qui tendent à les différencier et influencer sur les résultats. L’absence de réponse du site gouvernement.fr lors du crawl lancée sur les archives 2020, suite à un problème technique, explique l’absence de ce nœud essentiel sur la première cartographie. Les différences de politique de collecte, plus soutenues en 2020 qu’en 2021, tendent à rendre la cartographie de 2021 plus lâche. Au contraire, le crawl du web vivant en intégrant un plus grand nombre de liens dans l’analyse et donc des liens structurels préexistants à la pandémie renforce les effets d’hypercentralité – les algorithmes tendent alors à dissoudre certains clusters observés pour les cartes de 2020 et 2021, en particulier le cluster des blogs de vulgarisation scientifique bien visibles sur les cartes de 2020 et 2021.